重启dn导致集群不能写入数据,几百个任务都失败了, 经过一个通宵的折腾,记录一下这次重大事故。
报错日志
1 | DataStreamer Exception |
报错的日志各种误导,走了很多弯路,只说一下,最终解决了这个问题的方法:
网上有人出现这个问题是格式化解决,它们日志是There are 0 datanode(s) running and no node(s) are excluded in this operation.我的hdfs集群是正常的所有节点都在,只是不能写入数据。
我用的分层策略是One_SSD,查看了DFS Storage Types,发现disk的空间不够。

解决步骤
ssd磁盘的机器和普通磁盘的机器分2个角色组
普通组不加[SSD]
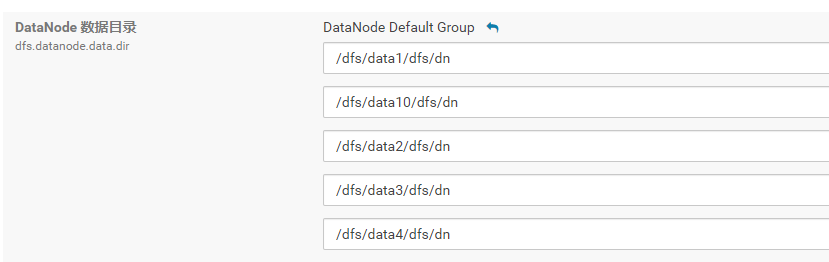
SSD组
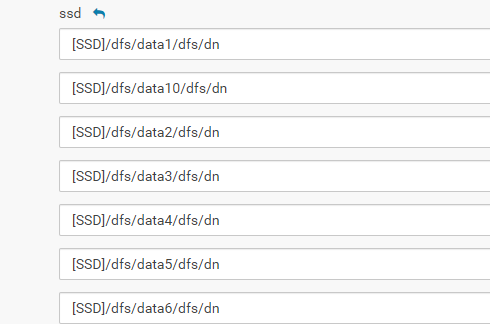
重启datanode
坑、 HDFS分层存储
通过在目录路径开头的括号中添加存储类型,为每个不是标准磁盘的DataNode数据目录指定存储类型。例如:
[SSD]/dfs/dn1
[DISK]/dfs/dn2
[ARCHIVE]/dfs/dn3
分层存储,官网并没有要求重启datanode,而且也没有说明要分组设置。只是刷新集群配置。其实并没有生效,给以后重启datanode留下了隐患。