磁盘读写测试
FIO安装
wget http://brick.kernel.dk/snaps/fio-2.2.5.tar.gz
yum install libaio-devel
tar -zxvf fio-2.2.5.tar.gz
cd fio-2.2.5
make
make install
1 | 测试: |
FIO安装
wget http://brick.kernel.dk/snaps/fio-2.2.5.tar.gz
yum install libaio-devel
tar -zxvf fio-2.2.5.tar.gz
cd fio-2.2.5
make
make install
1 | 测试: |
USDP部署操作指南:https://mp.weixin.qq.com/s/COnkLXPTWL5OK1PFYooThw?scene=25#wechat_redirect
bash repair.sh initAll 这个步骤大约要30多分钟,重复执行也慢。
注意:
1.在repair-host-info-add.properties文件中,仅需配置每次新增的节点信息即可,若存在已修复过的节点信息时,在下次运行“repair.sh initSingle”指令前,请清除。
2.jdk 安装在 /opt/module 下面,不允许随意删除,否则 java 环境失效。
3.数据库密码中不得包含 “@” 。
4.主机名设置不得包含 “_”,"-" 。
启动服务 bin/stop-udp-server.sh
查看日志目录 /var/log/udp
参考帮助 https://www.bilibili.com/video/BV1Cf4y1U7gn?from=search&seid=14731760489436726457
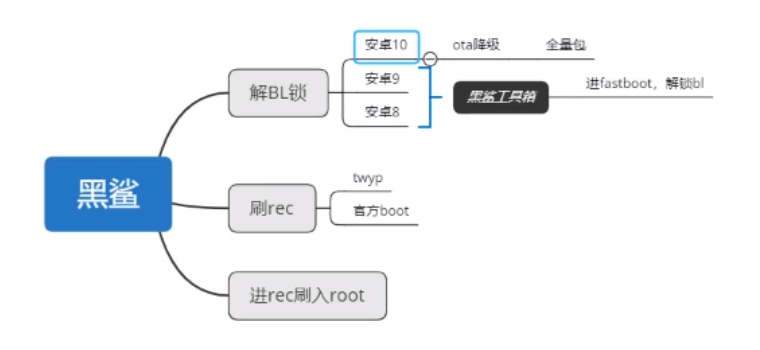
需要用到的文件
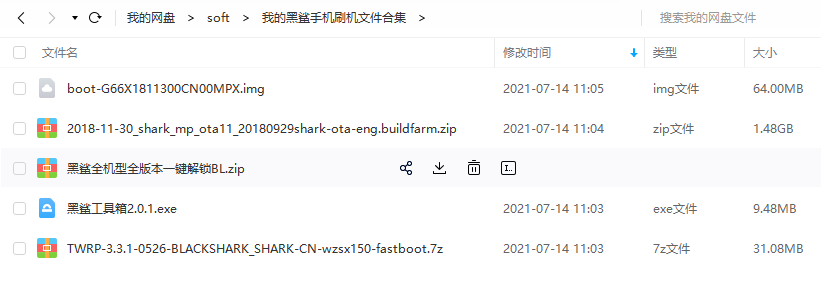
黑鲨1代
系统版本:G66X1811300CN00MPX安卓版本:8.1下载地址:https://ota-1256119282.file.myqcloud.com/SKR-A0/2018-11-30_shark_mp_ota11_20180929shark-ota-eng.buildfarm.zip
系统版本:G66X1905170CN00MPP安卓版本:P(安卓9)下载地址:https://ota-1256119282.file.myqcloud.com/SKR-A0/shark-ota-eng.buildfarm_2019-05-17_sdm845_p_mp_ota1_20190430.zip
刷机的准备工作:
1、根据自己机型下载对应版本型号的黑鲨手机全量包到电脑,将文件重命名为update.zip
一 配置管理规范
所有设备信息必须录入配置管理系统,在配置系统中能随时查询到现网业务的部署分布情况 具体信息待配置管理系统建立后再补充
主机命名规范
网卡vlan规范
安全策略命名规范
监控/部署/插件/模块命名规范
版本命名规范
二 文件系统管理规范
2.1 文件布局
| COMMAND | DESC |
|---|---|
| 查看 | |
| docker images | 列出所有镜像(images) |
| docker ps | 列出正在运行的容器(containers) |
| docker ps -a | 列出所有的容器 |
| docker pull centos | 下载centos镜像 |
| docker top ‘container’ | 查看容器内部运行程序 |
| 容器 | |
| docker exec -it 容器ID sh | 进入容器 |
| docker stop ‘container’ | 停止一个正在运行的容器,‘container’可以是容器ID或名称 |
| docker start ‘container’ | 启动一个已经停止的容器 |
| docker restart ‘container’ | 重启容器 |
| docker rm ‘container’ | 删除容器 |
| docker run -i -t -p :80 LAMP /bin/bash | 运行容器并做http端口转发 |
| docker exec -it ‘container’ /bin/bash | 进入ubuntu类容器的bash |
| docker exec -it /bin/sh | 进入alpine类容器的sh |
docker rm docker ps -a -q |
删除所有已经停止的容器 |
| docker kill $(docker ps -a -q) | 杀死所有正在运行的容器,$()功能同`` |
| 镜像 | |
| docker build -t wp-api . | 构建1个镜像,-t(镜像的名字及标签) wp-api(镜像名) .(构建的目录) |
| docker run -i -t wp-api | -t -i以交互伪终端模式运行,可以查看输出信息 |
| docker run -d -p 80:80 wp-api | 镜像端口 -d后台模式运行镜像 |
| docker rmi [image-id] | 删除镜像 |
| docker rmi $(docker images -q) | 删除所有镜像 |
| docker rmi $(sudo docker images --filter “dangling=true” -q --no-trunc) | 删除无用镜像 |
| docker run --help | 帮助 |
更多命令查看Docker 命令大全 | 菜鸟教程
1 | docker run --name ubuntu -it ubuntu bash |
期望结果:在ubuntu 镜像中添加 apache,将新的镜像保存到私有仓库中
1 | docker exec -it ubuntu bash |
1 | hadoop jar /opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar pi \ |
1 | sudo -u hdfs hadoop jar /opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/hadoop-mapreduce-client-jobclient-3.0.0-cdh6.0.1-tests.jar TestDFSIO \ |
Windows Server版本 安装参考 https://blog.51cto.com/professor/2411436
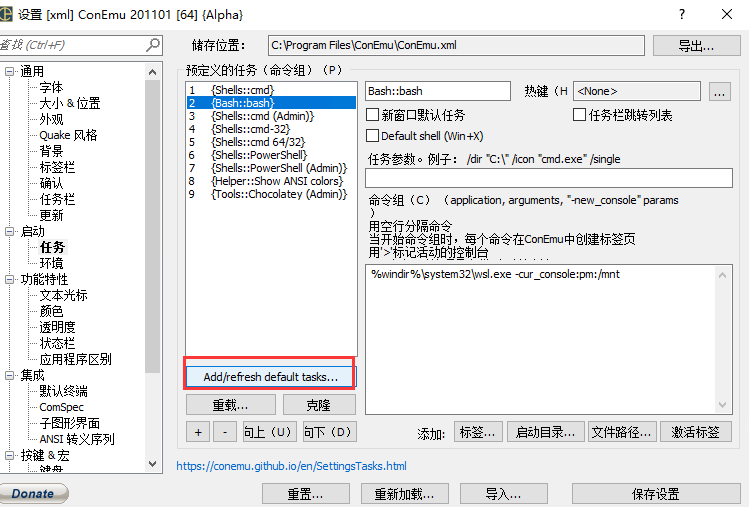
注意:如果先安装的ConEmu ,可能没有bash ,刷新一系default tasks,如下图:
win10版本 参考之前写的文档:
Win10 Subsystem Linux : Ubuntu 的root密码
每次开机都有一个新的root密码。我们可以在终端输入命令 sudo passwd,
然后输入当前用户的密码,enter,终端会提示我们输入新的密码并确认,
此时的密码就是root新密码。修改成功后,输入命令 su root,再输入新的密码就ok了。
win10 linux子系统设置默认用户
云计算的核心竞争力是运维!
系统架构师(偏管理):网络 系统 数据库 开发 云计算 自动化 运维管理 服务管理 项目管理 测试 业务
专注于某一领域
解决方案架构师
阿里云:
SLB LVS + Tengine(Nginx)
ECS KVM
物理设备层面:
1.服务器标签化、设备负责人、设备采购详情、设备摆放标准
2.网络划分、远程控制卡、网卡端口
3.服务器机型、硬盘、内存统一,根据业务分类
4.资产命名规范、编号规范、类型规范
5.监控标准
操作系统层面
1.操作系统版本
2.系统初始化(配置DNS、NTP、内核参数调优)
3.基础Agent配备(Zabbix agent、logstash agent、salt minion)
4.系统监控标准(CPU、内存、硬盘、网络、进程)
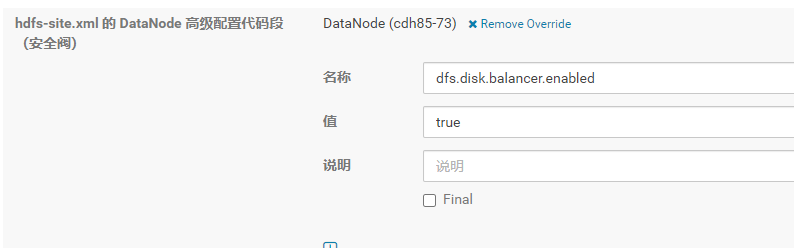
1.设置dfs.disk.balancer.enabled 为true , 可以单个datanode设置,重启单个datanode生效。
1 | <property> |
1.创建均衡任务并生成计划任务配置文件
sudo -u hdfs hdfs diskbalancer -plan cdh85-73
1 | [root@cdh85-73 tmp]# sudo -u hdfs hdfs diskbalancer -plan cdh85-73 |
注意: 这个路径是HDFS的路径,不是本地路径
2.查看配置文件
1 | [root@cdh85-73 tmp]# hdfs dfs -ls /system/diskbalancer/2021-Apr-29-16-45-51 |
矿池的具体接入教程描述得非常浅显易懂了,这里我就不做重复搬运了,直接参考 Chia挖矿教程
linux P盘
1 | nohup /opt/chia-plotter/chia-plotter-linux-amd64 -action plotting -plotting-fpk 0x85f80829a93d960313a99ca5482703fea2caae1d07db589344e76eba135db14c8f70d08dadc991805ae917d61626fd8d -plotting-ppk 0x970214947045bd1c6fbb0b3b3499dafab837eb26b58356504aea4d8ee19e9c5c064a5dfdad0cb5f7f047e0030f088a65 -plotting-n 1 -b 8000 -t /data1/chia -d /opt/chia >> plots2.log 2>&1 & |
晒一下收益效果:
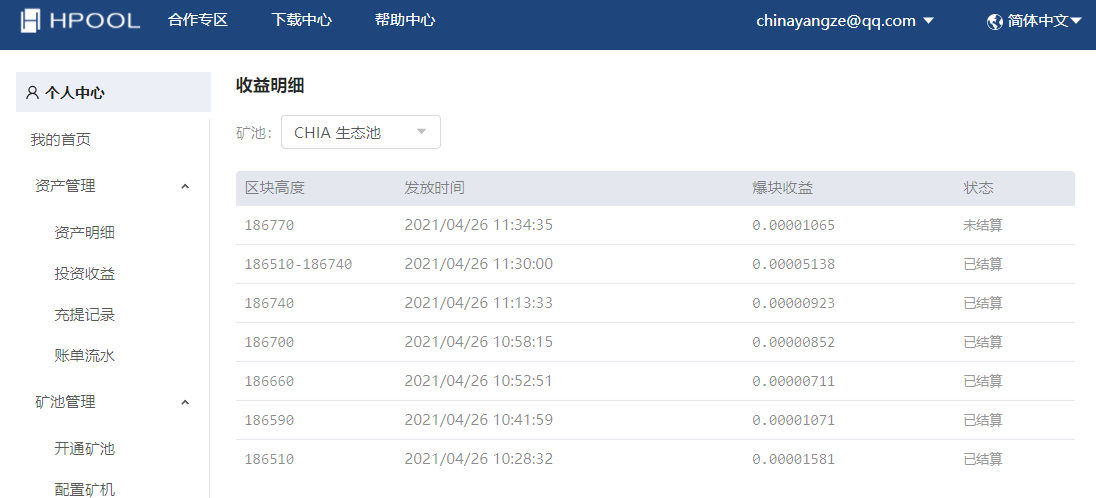
谋杀SSD磁盘
https://www.expreview.com/78802.html
生成一个K=32文件大概需要6.5小时,生成三个K33两个K32文件总共占了829GB的硬盘空间,而HDD的写入量是840.1GB,但SSD的读写非常厉害,整个P盘过程,SSD读取11.8TB,写入12.06TB,因为SSD的写入次数是有限的,把这个6TB的红盘P满虽然不至于把SSD写死,但磨损也很厉害。