xargs可以将输入内容(通常通过命令行管道传递),转成后续命令的参数,通常用途有:
- 命令组合:尤其是一些命令不支持管道输入,比如
ls。 - 避免参数过长:xargs可以通过
-nx来将参数分组,避免参数过长。
使用语法如下
1 | Usage: xargs [OPTION]... COMMAND INITIAL-ARGS... |
入门例子
首先,创建测试文件
1 | touch a.js b.js c.js |
接着,运行如下命令:
1 | ls *.js | xargs ls -al |
输出如下:
xargs可以将输入内容(通常通过命令行管道传递),转成后续命令的参数,通常用途有:
ls。-nx来将参数分组,避免参数过长。使用语法如下
1 | Usage: xargs [OPTION]... COMMAND INITIAL-ARGS... |
首先,创建测试文件
1 | touch a.js b.js c.js |
接着,运行如下命令:
1 | ls *.js | xargs ls -al |
输出如下:
重启dn导致集群不能写入数据,几百个任务都失败了, 经过一个通宵的折腾,记录一下这次重大事故。
1 | DataStreamer Exception |
网上有人出现这个问题是格式化解决,它们日志是There are 0 datanode(s) running and no node(s) are excluded in this operation.我的hdfs集群是正常的所有节点都在,只是不能写入数据。
我用的分层策略是One_SSD,查看了DFS Storage Types,发现disk的空间不够。

ssd磁盘的机器和普通磁盘的机器分2个角色组
普通组不加[SSD]
解决方案:
1 | datetime.date(2020, 11, 9).strftime("%-m月%-d日") |
1 | datetime.date(2020, 11, 9).strftime("%#m月%#d日") |
语法格式
1 | beeline -n username -p password -u jdbc:hive2://host:10000 --verbose=true --showHeader=false --outputformat=tsv2 --color=true -e "select * from ${database}.${tablename}" > ${tableName}.csv |
通过 outputformat 指定输出格式
–outputformat=[table/vertical/csv/tsv/dsv/csv2/tsv2] == 指定输出格式
–delimiterForDSV="*" ‘&’ 前提(–outputformat=dsv) 指定分隔符
不同格式对应的分隔符如下表:
| 格式 | 分隔符 |
|---|---|
| table | 表格式 |
| vertical | 如下所示 |
| csv | ‘,’ 逗号(元素包含引号) |
| tsv | ‘\t’ 制表符(元素包含逗号) |
| dsv | 默认‘|’ 竖线分割,可通过delimiterForDSV指定分隔符 |
| csv2 | ‘,’ 逗号(不含引号) |
| tsv2 | ‘\t’ 制表符(不含引号) |
说明:
csv格式 == 查询元素有’'单引号
csv2格式没有单引号
tsv,tsv2同上
create table xxx as select的方式创建的表默认存储格式是text,所以要注意了假如as select的是其他格式的比如RCFile,则可能会导致一行变多行的情况(因为RCFile格式的可能字段包含换行符等),所以必须要加上
create table xxx stored as RCFile as select…
所以使用这种方式建表注意加上指定的存储格式。
测试示例:
1 | drop table if exists decision_model.member_close_reason; |
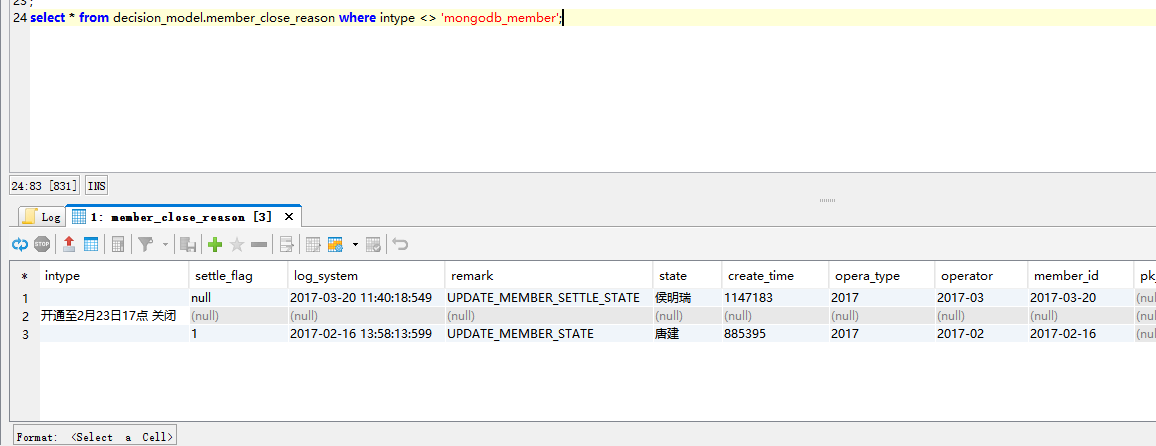
正确的应该加上指定的存储格式。
1 | drop table if exists decision_model.member_close_reason; |
1 | log4j.rootLogger=WARN,stdout,A1 |
1 | !/bin/bash |
1 | nohup sh ./stream_CbDimStreamDriver.sh > /dev/null 2>&1 |
参考: http://mkuthan.github.io/blog/2016/09/30/spark-streaming-on-yarn/
-移动数据 交易 路由 网络
具体场景;
挂载全球文件
版本管理功能
数据库
加密平台
各种类型cdn
永久访问的链接
ipfs initError: cannot acquire lock: can't lock file删除其后边给出的repo.lock文件即可ipfs id 查看当前节点id等信息ipfs config show ipfs配置信息ipfs daemon从官网下载hbck2 执行文件
http://hbase.apache.org/downloads.html
cdh官网的使用帮助
1 | cd /opt/hbase-operator-tools-1.0.0/hbase-hbck2 |
移动表的数据到另外一个服务器
1 | # 语法:move 'encodeRegionName', 'ServerName'`` |